Single-Server Deployments with Terraform, Docker Compose, and GitHub Actions
A single cloud server can affordably power a range of services. In many cases, the vertical scalability capabilities of a single host are enough to cover the needs of many business applications for years, if not indefinitely. Deploying on top of plain cloud servers requires more expertise and oversight and has different risks and costs than relying on popular PaaS offerings like Heroku. There are also tools like Dokku that facilitate deploying to a single server with a good developer experience. But let's assume that you don't want to use any of these, but prefer to build your deployment pipeline on top of lower-level building blocks like Terraform, an infrastructure provisioning tool, Docker Compose, a multi-container manager, and GitHub Actions, a CI/CD automation tool. This post shows one way to do that - ok, cheating a little by also relying on Docker Hub, S3, Route53, and Let's Encrypt for convenience, but still keeping recurring hosting costs minimal.
Motivation
It can be hard to justify rationally deploying services on top of raw cloud capacity and relatively low-level orchestration and infrastructure tools. But it can be fun and educational and give a warm fuzzy feeling that you're supposedly minimizing your hosting costs, provided you don't put any price on the time you spend building, maintaining, and monitoring custom deployment pipelines - not to mention any incident mitigations at odd hours. In principle, it can be suitable even for production systems, provided that an occasional loss of availability or the risk of losing a few hours' worths of data are not deal-breakers.
I used to build desktop Linux systems from components, foolhardily combining hardware components with experimental Linux support. Most of the time, I even got them to work after spending hours compiling kernel modules and tinkering with Xorg settings. Albeit occasionally frustrating, I got comfortable on the command line and developed a liking for a deeper understanding of the complexity of Linux systems.
Another reason is that, while managed services are generally very reliable, sometimes they fail, and there's very little you can do besides sending filing support tickets and hoping that someone does something. Managing infrastructure and services yourself lets you play the hero when (not if) it goes down. Root access to all parts of the system makes it possible to customize it to the degree that is not necessarily possible in managed services. For example, you may want to add a custom PostgreSQL extension not supported by a hosting provider.
Overview
The deployment setup in this post uses Terraform to create:
- a cloud server at UpCloud, a hosting provider with good support and fast servers,
- an A DNS record at Route53 pointing to the cloud server IP address,
- a CNAME DNS record with a different hostname pointing to the hostname of the cloud server, and
- an S3 bucket to store PostgreSQL database backups.
The base system for the cloud server is Ubuntu 20.04, on top of which an initialization script installs sshguard, Munin, Docker, and Docker Compose.
Docker Hub hosts the image for a custom Node.js application.
After the server is up and running, a GitHub Actions workflow syncs the Docker Compose configuration file with three services (Nginx, Node.js, and PostgreSQL) and runs Docker Compose remotely.
Let's Encrypt's certbot Docker image manages SSL Certificates.
Creating S3 Bucket for Terraform State
Terraform transforms declarative definitions into a series of API commands to bring up cloud resources like servers and DNS records. It uses a state file to track metadata and improve performance between deployments. Since this setup uses GitHub Actions to run Terraform and GitHub Actions runners do not have a persistent file system, an S3 bucket serves instead as a place to store the state file. This bucket must be created separately as a one-off manual step with an IAM user allowed to create S3 buckets.
You can create an S3 bucket for the Terraform state file through AWS Console or by running Terraform locally. To create an S3 bucket locally, we need one Terraform definition file main.tf. The definition file below uses the AWS provider to interact with AWS API and specifies a single aws_s3_bucket resource:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
provider "aws" {
region = "eu-west-1"
}
resource "aws_s3_bucket" "bucket" {
bucket = "my-project-tf-state" # CHANGE HERE
}
main.tf, Terraform definition to create an S3 bucket
You can run Terraform locally with Terraform's Docker image. Assuming AWS credentials are created (see Configuring AWS CLI), you can expose them to the Docker container by volume-mounting ~/.aws. First, you must initialize a Terraform working directory by running the init command.
docker run -it \
-v $(pwd):/workspace \
-v ~/.aws:/root/.aws \
-w /workspace \
hashicorp/terraform:1.2.5 init
running Terraform in Docker
The command above creates a Dependency Lock File and installs the required dependencies. After initialization succeeds, you can execute the apply command to create the bucket:
docker run -it \
-v $(pwd):/workspace
-v ~/.aws:/root/.aws
-w /workspace \
hashicorp/terraform:1.2.5 apply
Terraform will present the plan and requires you to confirm it by typing "yes" before proceeding. Provided that everything went smoothly until now, you should see the following message:
aws_s3_bucket.bucket: Creating...
aws_s3_bucket.bucket: Creation complete after 6s [id=my-project-tf-state]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Server Initialization Script
After provisioning a cloud server with a base system, you can install more packages and configurations with an initialization script. The initialization script below first installs sshguard, Munin, Docker, and Docker Compose. Then it tweaks the unattended-upgrades configuration to reboot the server if needed and prune unused packages to conserve disk space.
#!/bin/bash
apt-get update
apt-get install -y \
software-properties-common \
add-apt-key \
munin \
sshguard
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
apt-get update
apt-get install -y docker-ce docker-ce-cli containerd.io
apt-get upgrade -y
# enable automatic reboots and package pruning
# to keep disk usage in check
sed \
-e 's/\/\/Unattended-Upgrade::Automatic-Reboot/Unattended-Upgrade::Automatic-Reboot/' \
-e 's/\/\/Unattended-Upgrade::Remove-Unused-Kernel-Packages/Unattended-Upgrade::Remove-Unused-Kernel-Packages/' \
-e 's/\/\/Unattended-Upgrade::Remove-New-Unused-Dependencies/Unattended-Upgrade::Remove-New-Unused-Dependencies/' \
< /etc/apt/apt.conf.d/50unattended-upgrades \
> /tmp/50unattended-upgrades
mv /tmp/50unattended-upgrades /etc/apt/apt.conf.d/
DOCKER_CONFIG=${DOCKER_CONFIG:-$HOME/.docker}
mkdir -p $DOCKER_CONFIG/cli-plugins
DOCKER_COMPOSE=$DOCKER_CONFIG/cli-plugins/docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.6.1/docker-compose-linux-x86_64 -o $DOCKER_COMPOSE
chmod +x $DOCKER_COMPOSE
reboot
init-server.sh: server initialization script
Creating Server and DNS Records with Terraform
With the S3 bucket for Terraform state created, you can proceed to create a server, DNS records, and an S3 bucket to store backups. The s3 backend stores Terraform state to the S3 bucket. In addition to the AWS provider, I'll be using the UpCloud Terraform provider and borrowing the server definitions from UpCloud's Terraform starter tutorial.
Organizing Terraform definitions in multiple files (and folders) is a good practice in a larger project. For this small setup, it suffices to place the configuration in two files provider.tf and server1.tf in the folder terraform:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
upcloud = {
source = "UpCloudLtd/upcloud"
}
}
backend "s3" {
bucket = "my-project-tf-state" # CHANGE THIS
key = "server1"
region = "eu-west-1"
}
}
provider "aws" {
region = "eu-west-1"
}
provider "upcloud" {
}
terraform/provider.tf: Terraform configuration for providers and backends
The resource definition file main.tf creates three resources:
- The resource upcloud_server adds a cloud server at UpCloud according to the specified size of the instance (CPU, memory, and storage), the base system, and the SSH keys (the Terraform variables
SSH_PRIVATE_KEYandSSH_PUBLIC_KEY) to connect to the instance and an initialization script. - The resource aws_route53_record adds an A DNS record pointing at the server instance public network interface at Route53.
- The resource aws_s3_bucket adds an S3 bucket to store database backups.
variable "SSH_PRIVATE_KEY" {
type = string
}
variable "SSH_PUBLIC_KEY" {
type = string
}
resource "upcloud_server" "server1" {
hostname = "server1.terolaitinen.fi"
zone = "de-fra1"
plan = "1xCPU-1GB"
template {
size = 25
# Template UUID for Ubuntu 20.04
storage = "01000000-0000-4000-8000-000030200200"
}
network_interface {
type = "public"
}
network_interface {
type = "utility"
}
login {
user = "root"
keys = [
var.SSH_PUBLIC_KEY
]
create_password = false
}
connection {
host = self.network_interface[0].ip_address
type = "ssh"
user = "root"
private_key = var.SSH_PRIVATE_KEY
}
provisioner "remote-exec" {
script = "init-server.sh"
}
}
resource "aws_route53_record" "server1" {
zone_id = "YOUR_HOSTED_ZONE_ID"
name = "server1.terolaitinen.fi"
type = "A"
ttl = "300"
records = [
upcloud_server.server1.network_interface[0].ip_address
]
}
resource "aws_route53_record" "server" {
zone_id = "YOUR_HOSTED_ZONE_ID"
name = "app"
type = "CNAME"
ttl = "300"
records = [
"server1.terolaitinen.fi"
]
}
resource "aws_s3_bucket" "bucket" {
bucket = "my-project-server1"
}
terraform/main.tf: Terraform definitions for an UpCloud server and a DNS record
In addition to volume-mounting AWS credentials, you need to pass UpCloud API credentials in UPCLOUD_USERNAME and UPCLOUD_PASSWORD environment variables and SSH credentials in TF_VAR_OPENSSH_PRIVATE_KEY and TF_VAR_OPENSSH_PUBLIC_KEY when applying:
docker run -it \
-v $(pwd):/workspace \
-v ~/.aws:/root/.aws \
-e TF_VAR_OPENSSH_PRIVATE_KEY \
-e TF_VAR_OPENSSH_PUBLIC_KEY \
-e UPCLOUD_USERNAME \
-e UPCLOUD_PASSWORD \
-w /workspace \
hashicorp/terraform:1.2.5 apply
passing environment variables and volume-mounting AWS credentials to Terraform running in Docker
Running Terraform in GitHub Actions
Changes to infrastructure are less frequent than application updates, but due to their possible destructive nature, it's good to keep the number of moving parts to a minimum and dedicate a separate repository for Terraform configuration files. This standardizes the process of making changes to the infrastructure, that is, always running the same version of Terraform. It also allows other contributors to open PRs to make changes to the infrastructure without handing out cloud provider credentials.
Creating a script to invoke Terraform keeps GitHub Actions workflows tidy and makes it easier to run it in the same way on your local computer. The script below, unlike before, passes AWS credentials in the environment and does not volume-mount the folder ~/.aws.
#!/bin/bash
docker run -it \
-v $(pwd):/workspace \
-e AWS_ACCESS_KEY_ID \
-e AWS_SECRET_ACCESS_KEY \
-e TF_VAR_SSH_PRIVATE_KEY \
-e TF_VAR_SSH_PUBLIC_KEY \
-e UPCLOUD_USERNAME \
-e UPCLOUD_PASSWORD \
-w /workspace \
hashicorp/terraform:1.2.5 "$@"
scripts/terraform.sh: a script to run Terraform in Docker
Before approving a PR containing changes to the infrastructure it's good to check that the Terraform plan is sensible. The GitHub Actions workflow below triggers when a PR is opened, reopened or synchronized and posts the output of terraform plan as a PR comment using the action peter-evans/create-update-comment:
name: PR
on:
pull_request:
env:
S3_BUCKET: my-project-tf-state
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
TF_VAR_SSH_PRIVATE_KEY: ${{ secrets.SSH_PRIVATE_KEY }}
TF_VAR_SSH_PUBLIC_KEY: ${{ secrets.SSH_PUBLIC_KEY }}
UPCLOUD_USERNAME: ${{ secrets.UPCLOUD_USERNAME }}
UPCLOUD_PASSWORD: ${{ secrets.UPCLOUD_PASSWORD }}
permissions:
contents: read
issues: write
pull-requests: write
jobs:
plan:
runs-on: ubuntu-latest
steps:
- name: Git Checkout
uses: actions/checkout@v3
- name: Terraform Init
run: cd terraform && ../scripts/terraform.sh init
- name: Terraform Plan
id: plan
run: |
# wrap plan in Markdown code block
echo -n '```' > /tmp/terraform-plan \
&& cd terraform && ../scripts/terraform.sh plan -no-color >> /tmp/terraform-plan \
&& echo -n '```' >> /tmp/terraform-plan # end of code block
- name: Create comment
uses: peter-evans/create-or-update-comment@v2
with:
issue-number: ${{ github.event.pull_request.number }}
body-file: /tmp/terraform-plan
.github/workflows/main.yaml: GitHub Actions workflow for building and deploying Docker image
The workflow posts the terraform plan output as a PR comment, but does not preserve it for terraform apply. Running terraform apply later may thus have other effects in principle.
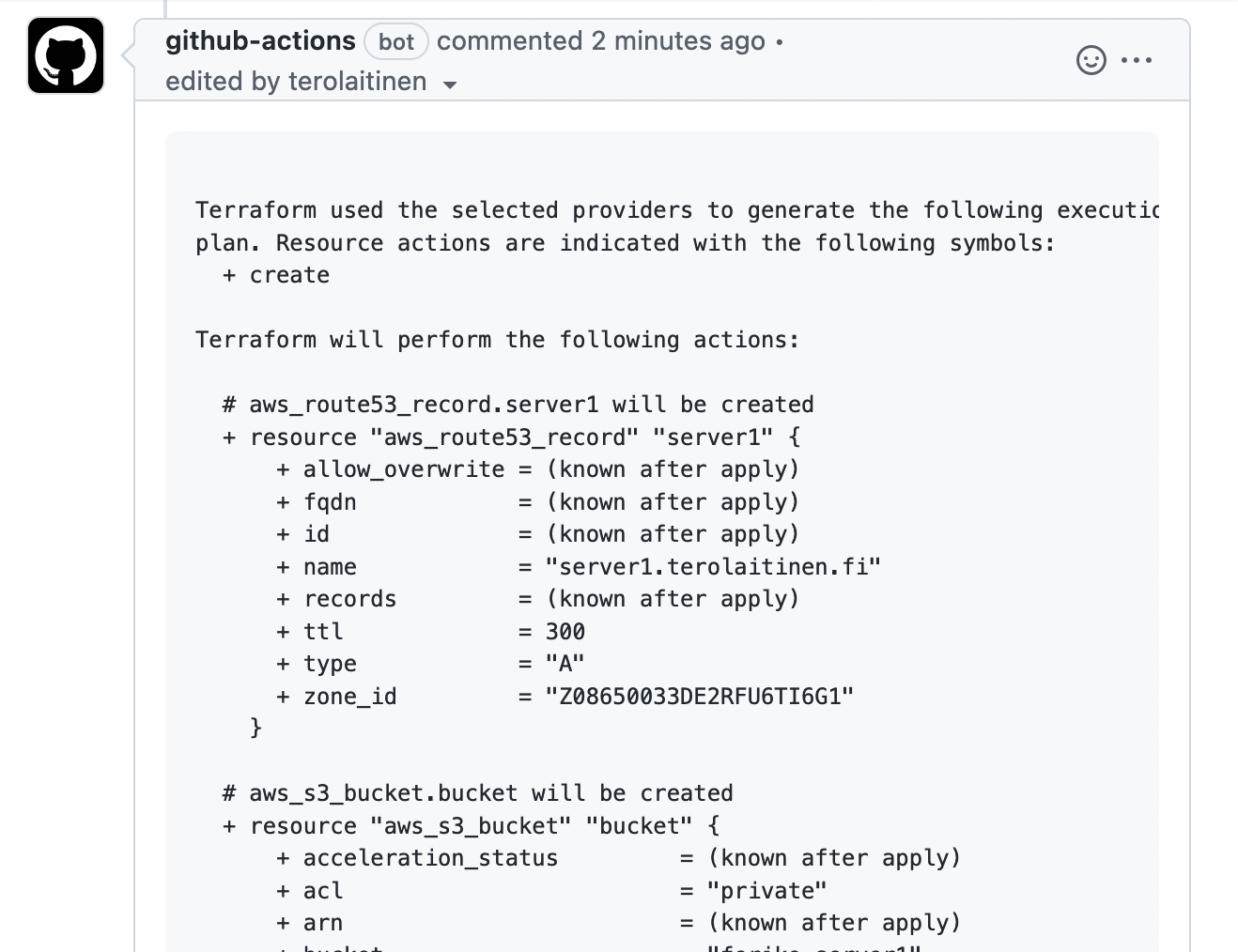
If the plan in the comment looks good, you can use the GitHub Actions workflow below that triggers when a new commit is pushed to the main branch to run terraform apply.
name: Main
on:
push:
branches:
- 'main'
env:
S3_BUCKET: my-project-tf-state
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
TF_VAR_SSH_PRIVATE_KEY: ${{ secrets.SSH_PRIVATE_KEY }}
TF_VAR_SSH_PUBLIC_KEY: ${{ secrets.SSH_PUBLIC_KEY }}
UPCLOUD_USERNAME: ${{ secrets.UPCLOUD_USERNAME }}
UPCLOUD_PASSWORD: ${{ secrets.UPCLOUD_PASSWORD }}
jobs:
plan:
runs-on: ubuntu-latest
steps:
- name: Git Checkout
uses: actions/checkout@v3
- name: Terraform Init
run: cd terraform && ../scripts/terraform.sh init
- name: Terraform Apply
.github/workflows/main.yaml: GitHub Actions workflow that runs `terraform apply` when a new commit is pushed to the `main` branch.
After merging the PR, another workflow run applies changes to the infrastructure.
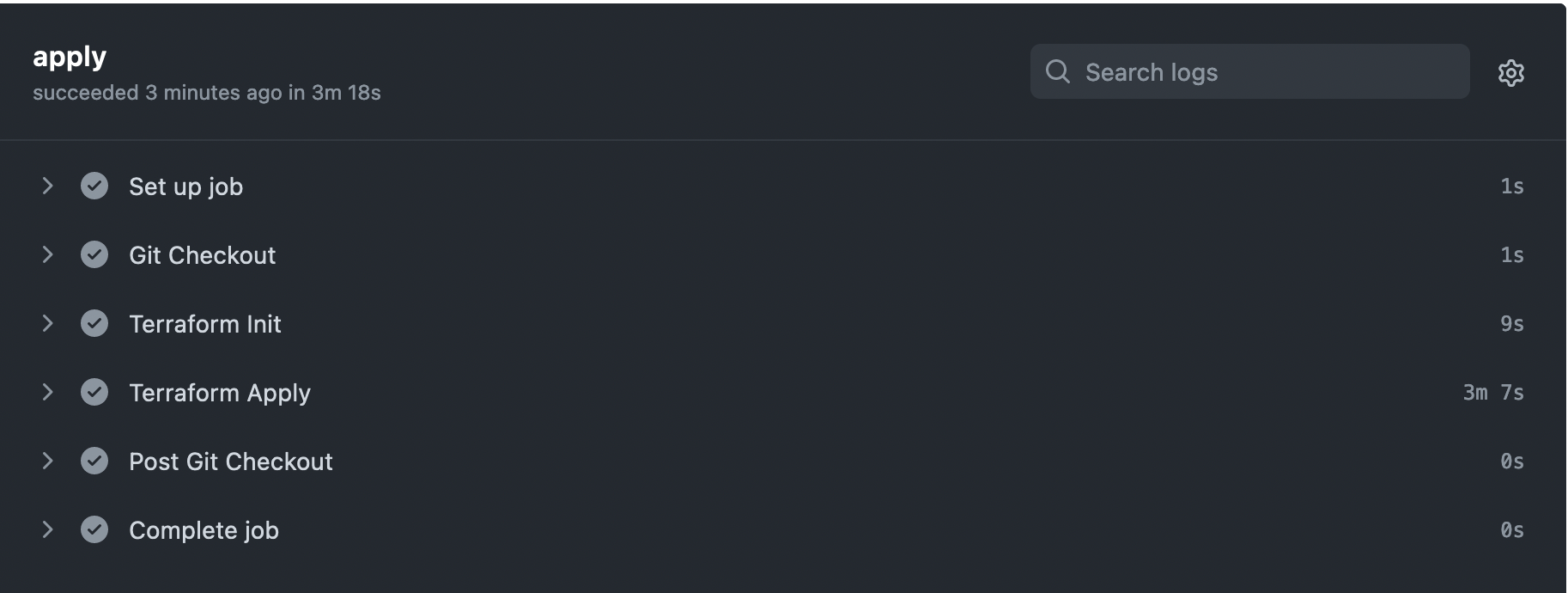
GitHub Actions running Terraform Apply
For increased peace of mind, you can tweak the GitHub Actions workflow files pr.yaml and main.yaml to store the plan generated by terraform plan in an S3 bucket and load it before applying. The Terraform documentation also has a guide on how to integrate Terraform into GitHub Actions workflows.
You can test that the server has been correctly provisioned by opening an SSH connection with the private key:
ssh -i id_rsa root@app.terolaitinen.fi
The authenticity of host 'app.terolaitinen.fi (XX.XX.XX.XX)' can't be established.
ED25519 key fingerprint is SHA256:XXXXXX.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'app.terolaitinen.fi' (ED25519) to the list of known hosts.
Welcome to Ubuntu 20.04.3 LTS (GNU/Linux 5.11.0-38-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri 30 Dec 2022 03:57:52 PM UTC
System load: 0.03 Users logged in: 1
Usage of /: 10.6% of 24.55GB IPv4 address for docker0: 172.17.0.1
Memory usage: 38% IPv4 address for eth0: XX.XX.XX.XX
Swap usage: 0% IPv4 address for eth1: 10.4.3.158
Processes: 100
* Are you ready for Kubernetes 1.19? It's nearly here! Try RC3 with
sudo snap install microk8s --channel=1.19/candidate --classic
https://microk8s.io/ has docs and details.
19 updates can be applied immediately.
8 of these updates are standard security updates.
To see these additional updates run: apt list --upgradable
New release '22.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Your Hardware Enablement Stack (HWE) is supported until April 2025.
Last login: Fri Dec 30 15:54:19 2022 from XX.XX.XX.XX
root@server1:~#
Connecting to the newly provisioned server with SSH
Simple Node.js Application
As a proof of concept, I'll include a minimal Node.js application to build and deploy as a custom Docker image. The application starts an HTTP server, connects to a PostgreSQL database, and responds to HTTP requests with a timestamp coming from the database.
import http from "http";
import pg from "pg";
const run = async () => {
const client = new pg.Client();
await client.connect();
const server = http.createServer(async (_req, res) => {
try {
const now = (await client.query("SELECT NOW() as now")).rows[0].now;
res.writeHead(200);
res.end(String(now));
} catch (error) {
console.log(error.stack);
}
});
server.listen(3000);
};
run();
a simple Node.js application that runs an HTTP server and connects to PostgreSQL
The two-stage Dockerfile copies the files needed to install dependencies and to transpile TypeScript sources:
FROM node:18 AS build
COPY package.json tsconfig.json yarn.lock /build/
COPY src /build/src
WORKDIR /build
RUN yarn --frozen-lockfile
RUN yarn build
FROM node:18-slim
RUN apt-get update && apt-get install -y tini
ENTRYPOINT ["/usr/bin/tini", "--"]
ENV NODE_ENV production
COPY --from=build /build/dist /app/dist
COPY --from=build /build/node_modules /app/node_modules
WORKDIR /app
CMD ["node", "dist/main.js"]
Dockerfile to containerize a JavaScript application
To keep track of which version of the application is running and to roll back faster in case of trouble, you can include the git revision in the Docker image tag when building:
docker build -t docker_hub_username/app:$(git rev-parse HEAD) .
including git revision in Docker image tag
Docker Compose Configuration
With the server provisioned and Docker installed, the next step is to provide a configuration for Docker Compose. The example configuration file below defines three services:
- PostgreSQL, a database for the application.
- Node.js application in a custom Docker image
app. - Nginx, a reverse proxy, serves static files to verify Let's Encrypt certificate.
The Node.js application has two replicas so it can be restarted them without downtime.
The PostgreSQL data directory is volume-mounted so that it survives reboots. The Nginx container has three volume mounts: one for Let's Encrypt certificates, another for Let's Encrypt challenges, and the third for reverse proxy configuration.
The configuration references three environment variables:
APP_IMAGE_NAME: the name of the Docker image to start, e.g.,tlaitinen/app:18c1fc796e1ac8fc14c93da0ef396dffb9ba7efewith a default value so that it's possible to rundocker compose psanddocker compose logswithout specifying an image name.APP_PGUSER,APP_PGPASSWORD, andAPP_PGDATABASE: the PostgreSQL credentials the application uses to connect to the database.
version: '3'
services:
postgres:
image: "postgres:14"
container_name: postgres
environment:
- POSTGRES_PASSWORD=${APP_PGPASSWORD}
volumes:
- /data/postgresql:/var/lib/postgresql
restart: always
app:
image: "${APP_IMAGE_NAME:-tlaitinen/app:latest}"
restart: always
environment:
- PGHOST=postgres
- PGUSER=${APP_PGUSER}
- PGPASSWORD=${APP_PGPASSWORD}
- PGDATABASE=${APP_PGDATABASE}
depends_on:
- postgres
deploy:
replicas: 2
proxy:
image: "nginx:latest"
container_name: proxy
restart: always
depends_on:
- app
ports:
- "80:80"
- "443:443"
volumes:
- "/data/proxy/letsencrypt:/etc/letsencrypt"
- "/data/proxy/webroot:/usr/share/nginx/html"
- "/data/proxy/conf.d/app.conf:/etc/nginx/conf.d/app.conf"
docker-compose.yaml: Docker Compose configuration with three services
Since you may want to connect to the server from your local computer and also from GitHub Actions runner, it's convenient to define a script that passes the relevant environment variables. The script below logs into Docker Hub before running docker compose and prunes unused Docker images to safe disk space.
#!/bin/bash
if [ -z "$SERVER" ]; then
echo "Missing SERVER"
exit 1
fi
if ! rsync -e "ssh -o 'StrictHostKeyChecking no'" docker-compose.yaml root@${SERVER}: ; then
echo "Failed to copy docker-compose.yaml"
exit 1
fi
ssh -o 'StrictHostKeyChecking no' root@${SERVER} " mkdir -p /data/proxy/{conf.d,letsencrypt,webroot} /data/postgresql \
&& touch /data/proxy/conf.d/app.conf \
&& echo ${DOCKERHUB_PASSWORD} | docker login -u ${DOCKERHUB_USERNAME} --password-stdin \
&& APP_IMAGE_NAME=${APP_IMAGE_NAME} \
APP_PGUSER=${APP_PGUSER} \
APP_PGPASSWORD=${APP_PGPASSWORD} \
APP_PGDATABASE=${APP_PGDATABASE} \
docker compose $@
&& docker system prune -af"
scripts/compose.sh: running Docker Compose remotely
Building Docker Image in GitHub Actions
The Docker image for the application should be built whenever any of the assets included in the build stage change. In principle, we could detect this with git diff but in practice, it's easier and simpler to rebuild the image whenever the git repository's main branch's HEAD moves. After the image is built it needs to be pushed to Docker Hub. Then the new application can be deployed by instructing Docker Compose to pull and start a new image. The GitHub Actions workflow file below runs whenever someone pushes to the main branch. The workflow references four secrets:
DOCKERHUB_USERNAMEis your Docker Hub ID, not really a secret, but store in repo secrets for convenience.DOCKERHUB_TOKENis an API credentials token for your Docker Hub ID.APP_IMAGE_NAMEis the name of the Docker image to start.APP_PGUSERis the name of the role to connect to the PostgreSQL database with. I don't cover database schema creation here so I set it topostgres.APP_PGPASSWORDis the password for the PostgreSQL role. In this experiment I set it to matchPOSTGRES_PASSWORDtopostgresDocker container is created with.SERVER_HOSTNAME: the hostname of the server (app.terolaitinen.fi), not a secret, but it's convenient to store it in a secret to share it in multiple workflow definitions.
name: Main
on:
push:
branches:
- main
env:
APP_IMAGE_NAME: ${{ secrets.DOCKERHUB_USERNAME }}/app:${{ github.sha }}
SSH_AUTH_SOCK: /tmp/ssh_agent.sock
jobs:
build_and_deploy:
runs-on: ubuntu-latest
steps:
- name: Git Checkout
uses: actions/checkout@v3
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_PASSWORD }}
- name: Build image
run: docker build -t ${APP_IMAGE_NAME} .
- name: Push image
run: docker push ${APP_IMAGE_NAME}
- name: Add SSH private key to ssh-agent
run: |
ssh-agent -a $SSH_AUTH_SOCK > /dev/null
ssh-add - <<< "${{ secrets.SSH_PRIVATE_KEY }}"
- name: Deploy
env:
SERVER: ${{ secrets.SERVER_HOSTNAME }}
APP_PGUSER: ${{ secrets.APP_PGUSER }}
APP_PGPASSWORD: ${{ secrets.APP_PGPASSWORD }}
DOCKERHUB_USERNAME: ${{ secrets.DOCKERHUB_USERNAME }}
DOCKERHUB_PASSWORD: ${{ secrets.DOCKERHUB_PASSWORD }}
run: ./scripts/compose.sh up -d
.github/workflows/main.yaml: GitHub Actions workflow for building and deploying Docker image
After pushing a commit to the main branch, the workflow packages the TypeScript application in a Docker image and deploys it to the provisioned server.
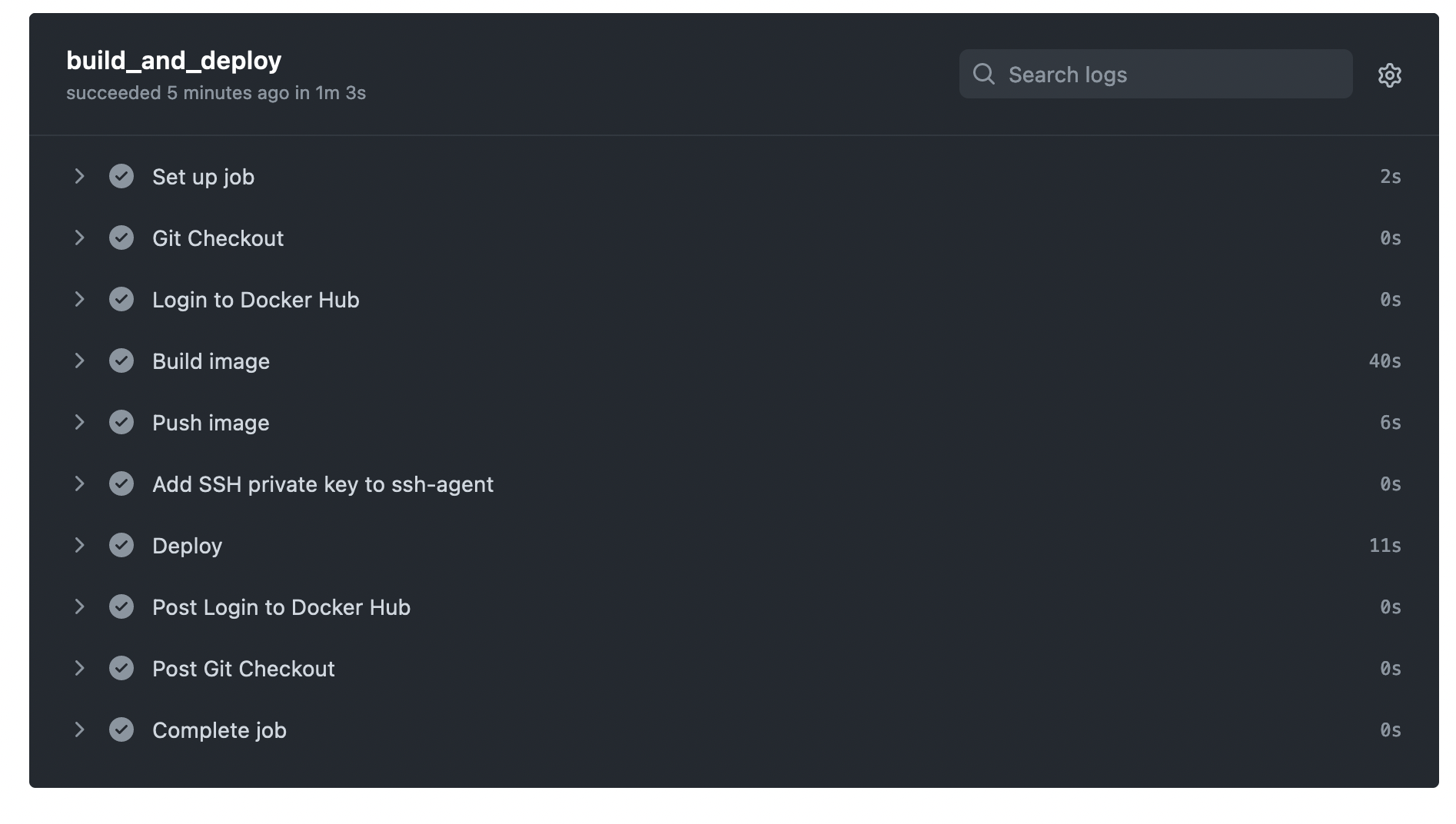
GitHub Actions building and deploying a Docker image
You can now verify that the Docker containers are running in the server.
ssh -i id_rsa root@app.terolaitinen.fi docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
18c3f6a00cf5 nginx:latest "/docker-entrypoint.…" 53 seconds ago Up 51 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp proxy
e1a6707df214 tlaitinen/app:15e89a134a0cf3ac270320a50ea8f6eb4bcde0e2 "/usr/bin/tini -- no…" 53 seconds ago Up 51 seconds root-app-1
52b809faaee6 tlaitinen/app:15e89a134a0cf3ac270320a50ea8f6eb4bcde0e2 "/usr/bin/tini -- no…" 53 seconds ago Up 51 seconds root-app-2
d0e104bf3e36 postgres:14 "docker-entrypoint.s…" 55 seconds ago Up 52 seconds 5432/tcp postgres
Verifying that Docker containers are running
Reverse Proxy Configuration and SSL Certificate
The deployment setup in this article uses nginx as the reverse proxy for the application and also as a static file server when requesting SSL certificates. The script below connects to the server through SSH and runs Certbot in Docker to request or to renew an SSL certificate. After that, it writes the Nginx configuration file to and restarts or reloads the reverse proxy. It expects two environment variables:
SERVER: the hostname of the server,EMAIL: the email address where Let's Encrypt sends
#!/bin/bash
if [ -z "$SERVER" ] || [ -z "$EMAIL" ]; then
echo "Missing SERVER or EMAIL"
exit 1
fi
ssh -T root@${SERVER} <<EOF
echo "
server {
listen 80;
server_name ${SERVER};
root /usr/share/nginx/html;
location / {
return 301 https://${SERVER}\\\$request_uri;
}
location /.well-known {
}
}
server {
listen 443 ssl;
server_name ${SERVER};
ssl_certificate /etc/letsencrypt/live/${SERVER}/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/${SERVER}/privkey.pem;
location / {
proxy_set_header Host \\\$host;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-For \\\$proxy_add_x_forwarded_for;
proxy_pass http://app:3000;
}
}
" > /data/proxy/conf.d/app.conf
if [ ! -d /data/proxy/letsencrypt/live/${SERVER} ]; then
docker run --rm \
-v /data/proxy/webroot:/webroot \
-v /data/proxy/letsencrypt:/etc/letsencrypt \
certbot/certbot certonly --agree-tos --renew-by-default \
--webroot --webroot-path=/webroot \
--email ${EMAIL} --non-interactive \
-d ${SERVER}
docker exec proxy service nginx restart
else
docker run --rm \
-v /data/proxy/webroot:/webroot \
-v /data/proxy/letsencrypt:/etc/letsencrypt \
certbot/certbot renew --webroot --webroot-path=/webroot
docker exec proxy service nginx reload
fi
EOF
./scripts/configure_proxy.sh: Requests/renews Let's Encrypt SSL certificate and adds reverse proxy configuration
The GitHub Actions workflow below runs every day at midnight (UTC), checks out the repository, configures the SSH private key and feeds the secrets SERVER_HOSTNAME and LETSENCRYPT_EMAIL when it runs the script above:
name: Proxy
on:
schedule:
- cron: '0 0 * * *'
workflow_dispatch:
env:
SSH_AUTH_SOCK: /tmp/ssh_agent.sock
jobs:
configure_proxy:
runs-on: ubuntu-latest
steps:
- name: Git Checkout
uses: actions/checkout@v3
- name: Add SSH private key to ssh-agent
run: |
ssh-agent -a $SSH_AUTH_SOCK > /dev/null
ssh-add - <<< "${{ secrets.SSH_PRIVATE_KEY }}"
- name: Configure Proxy
env:
SERVER: ${{ secrets.SERVER_HOSTNAME }}
EMAIL: ${{ secrets.LETSENCRYPT_EMAIL }}
run: ./scripts/configure_proxy.sh
.github/workflows/configure_proxy.yaml: GitHub Actions workflow for configuring the reverse proxy
The workflow can also be manually dispatched (see workflow_dispatch) so that you can configure the reverse proxy and request an SSL certificate immediately after configuring the workflow.
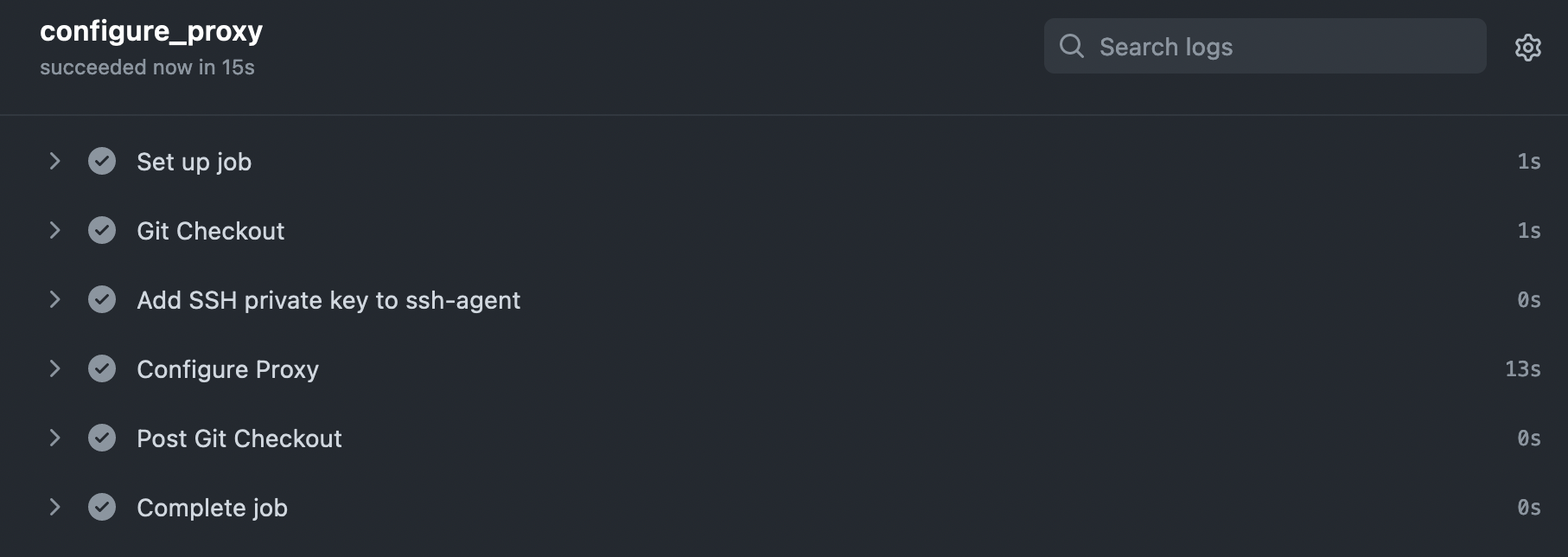
GitHub Actions configuring the reverse proxy
After a successful run, you should be able to make an HTTPS request and retrieve the current time from the PostgreSQL server through the reverse proxy and the Node.js application.
curl https://app.terolaitinen.fi
Sat Dec 31 2022 10:34:07 GMT+0000 (Coordinated Universal Time)
Connecting to the Node.js application through HTTPS
Storing Backups
Always sometimes, you end up losing data. It can happen due to a bug in the application, accidental deletions, hardware failure, or a third party. Backing up data keeps you in business when something happens and helps you sleep better in the meanwhile. In this deployment setup, I focus on taking daily backups of the PostgreSQL database. However, if the budget permits, enabling full file system backups of the server may simplify and speed up the recovery process.
In case losing up to a day's worth of data is unacceptable, you probably stopped reading a long time ago and are already using managed PostgreSQL services like Aiven or AWS RDS, but another fun option would be to configure continuous archiving and point-in-time recovery.
Let's assume that daily backups are enough. The script below connects to the server through SSH, runs pg_dump and pipes the output to gzip and then to the AWS command line client, streaming the database dump in SQL format to the S3 bucket.
#!/bin/bash
if [ -z "$SERVER" ]
|| [ -z "$DATABASE" ]
|| [ -z "$AWS_ACCESS_KEY_ID ]
|| [ -z "$AWS_SECRET_ACCESS_KEY ]
|| [ -z "$S3_BUCKET" ]; then
echo "Missing SERVER, DATABASE, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY"
exit 1
fi
ssh -T root@${SERVER} <<EOF
docker exec postgres su -u postgres -c pg_dump ${DATABASE} \
| gzip \
| docker run \
-e AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
-e AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
amazon/aws-cli \
s3 cp - s3://${S3_BUCKET}/pg_dump/${DATABASE}/$(date +%Y-%m-%dT%H:%M:%S).sql.gz
EOF
./scripts/pg_dump.sh: dumps a PostgreSQL database, gzips it, and streams it to an S3 bucket
The GitHub Actions workflow below runs every day at midnight (UTC), checks out the repository, configures the SSH private key and feeds the appropriate secrets to the script above:
name: PostgreSQL backup
on:
schedule:
- cron: '0 0 * * *'
workflow_dispatch:
env:
SSH_AUTH_SOCK: /tmp/ssh_agent.sock
jobs:
pg_dump:
runs-on: ubuntu-latest
steps:
- name: Git Checkout
uses: actions/checkout@v3
- name: Add SSH private key to ssh-agent
run: |
ssh-agent -a $SSH_AUTH_SOCK > /dev/null
ssh-add - <<< "${{ secrets.SSH_PRIVATE_KEY }}"
- name: Run pg_dump.sh
env:
SERVER: ${{ secrets.SERVER_HOSTNAME }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
DATABASE: ${{ secrets.APP_PGDATABASE }}
S3_BUCKET: ${{ secrets.S3_BUCKET }}
run: ./scripts/pg_dump.sh
.github/workflows/pg_dump.yaml: a GitHub Actions workflow that runs the script pg_dump.sh daily
Conclusions
A single server can often be sufficient to power a wide range of services. You can optimize your recurring hosting costs by building on raw server capacity while leveraging cost-efficient automation (Terraform, Docker Compose, and GitHub Actions) and managed services (AWS Route53 and S3) where appropriate. Trying out this deployment setup was an itch I long wanted to scratch, but while writing this article, I realized that it would've been better to split it into shorter, more focused pieces. Covering all relevant aspects of a well-planned and automated single-server deployment in one article was overly ambitious, and this article falls short. For a proper server setup, you should have adequate monitoring, alerting (e.g., when disk space is low or logs are showing errors), storing server logs, and health checks. For example, GoAccess could be integrated into this setup to view server stats in real-time, and Munin could give an overview of system resources. GitHub Actions could work as a simple basis to implement health checks and alert by email on failed workflow runs. Security considerations alone would warrant a more extended discussion.
Using these building blocks, you have a lot of flexibility in tailoring the setup to your requirements. There's very little magic after the system is provisioned, so it's easy to understand it and tweak it as needed. As long as your backups processes are properly configured and occasional downtime is not a deal breaker, you can cost-effectively host a range of services on a single server.