Automating Partitioned Table Migrations with GitHub Actions
PostgreSQL supports table partitioning, which splits rows into multiple partitions for improved query performance and easier bulk data transfers. Partitioned tables are useful when data are regularly inserted into a table and only recently added rows are selected in active operation. Older table partitions can be detached, archived, and finally dropped. Changes to database schemas in production systems should be managed with schema migrations, version-controlled, and incrementally applied SQL scripts. Repeated schema migrations should be automated to avoid errors, save engineering time, and ensure they are run. GitHub Actions is a CI/CD automation service that executes jobs according to workflow definitions. This post shows how to use GitHub Actions to regularly open pull requests that manage table partition migrations.
Initial Database Schema with Partitioned Table
PostgreSQL supports three different ways to partition rows in a table:
- Range Partitioning: using one or more orderable columns
- List Partitioning: explicitly specifying row keys for each partition
- Hash Partitioning: using hash of partition key
Range partitioning is suitable for cases when rows include a timestamp and only more recently added rows are accessed regularly. A range-partitioned table is created by adding the PARTITION BY RANGE clause at the end of a CREATE TABLE statement.
CREATE TABLE samples (
time date not null,
data jsonb not null
) PARTITION BY RANGE (time);
It can be helpful to add an index on the key column.
CREATE INDEX samples_time_idx ON samples (time);
Schema Migrations with postgres-migrations
The migration library postgres-migrations, which I've chosen here for its simplicity, runs migration scripts sequentially and stores information on which migrations have already been run in the table migrations the library creates. You specify the ordering for migrations in file names:
migrations/00001_initial_schema.sql
migrations/00002_first_migration.sql
migrations/00003_second_migration.sql
file-named based ordering of migrations
The library does not include a command-line utility, so a minimal migration script is required:
import pg from "pg";
import { migrate } from "postgres-migrations";
const client = new pg.Client()
await client.connect();
try {
await migrate({client}, "migrations");
} finally {
await client.end();
}
scripts/migrate.mjs (why not TypeScript? Top-level await did not work out of the box. :/)
A PostgreSQL database can be created for testing in a Docker container with postgres image:
$ docker run --rm --name postgres -e POSTGRES_PASSWORD=password -p 5432:5432 postgres
Before running the initial migration, a role and a database need to be created:
$ docker exec -i postgres su -c psql postgres <<EOF
CREATE ROLE samples PASSWORD 'samples' LOGIN;
CREATE DATABASE samples OWNER samples;
EOF
Connection information can be supplied through environment variables:
$ PGHOST=localhost PGPORT=5432 PGUSER=samples PGPASSWORD=samples PGDATABASE=samples node scripts/migrate.mjs
After running the initial migration, the table samples is present:
$ docker exec -it postgres su -c "psql samples -c '\d samples'" postgres
Partitioned table "public.samples"
Column | Type | Collation | Nullable | Default
--------+-------+-----------+----------+---------
time | date | | not null |
data | jsonb | | not null |
Partition key: RANGE ("time")
Indexes:
"samples_time_idx" btree ("time")
Number of partitions: 0
Creating Schema Migrations for Table Partitions
Picking a suitable number of partitions for a partitioned table depends on the requirements. If one partition contains rows for one calendar month and only the last three months are ever queried, four attached partitions can be a good starting point. When the oldest partition is detached, it can still be kept in the database for one month to archive its contents to separate storage before deletion.
The following script create-partition.ts creates schema migration files to manage a configurable number of table partitions. It takes three command-line arguments:
- current date (in any format
Datecan parse), - name of the partitioned table
- number of active partitions
import fs from "fs";
import path from "path";
const date = process.argv[2];
const table = process.argv[3];
const partitions = parseInt(process.argv[4]);
if (!date || !table || !Number.isInteger(partitions)) {
console.log(
"Usage: create-partition.ts YYYY-MM TABLE PARTITION\nExample: create-partition.ts 2022-07 samples 4"
);
process.exit(1);
}
// finding existing partition migration files with a regex
const migrationFileNameRegex = new RegExp(
`^[0-9]{5}_${table}_[0-9]{4}_[0-9]{2}.sql$`
);
const partitionTableName = (monthStart: Date) =>
`${table}_${monthStart.getFullYear()}_${String(
monthStart.getMonth() + 1
).padStart(2, "0")}`;
const toDateString = (date: Date) => date.toISOString().slice(0, 10);
const createScript = (startDate: Date, endDate: Date) =>
`CREATE TABLE ${partitionTableName(startDate)}
PARTITION OF ${table}
FOR VALUES FROM ('${toDateString(startDate)}') TO ('${toDateString(endDate)}');
`;
const run = async () => {
const migrations = await fs.promises.readdir("migrations");
const numExistingPartitions = migrations.filter((fileName) =>
migrationFileNameRegex.test(fileName)
).length;
const migration = migrations.length + 1;
const partition = numExistingPartitions + 1;
const today = new Date(date);
const currentMonthStart = new Date(today.getFullYear(), today.getMonth(), 1);
const nextMonthStart = new Date(
currentMonthStart.getFullYear(),
currentMonthStart.getMonth() + 1,
1
);
const nextMonthEnd = new Date(
nextMonthStart.getFullYear(),
nextMonthStart.getMonth() + 1,
1
);
const partitionToDetachStartDate = new Date(
today.getFullYear(),
today.getMonth() - partitions,
1
);
const partitionToDropStartDate = new Date(
today.getFullYear(),
today.getMonth() - partitions - 1,
1
);
const detachScript = `ALTER TABLE ${table} DETACH PARTITION ${partitionTableName(
partitionToDetachStartDate
)};`;
const dropScript = `DROP TABLE ${partitionTableName(
partitionToDropStartDate
)};`;
const migrationScript = [
// first migration creates a partition for the current month
partition === 1 ? createScript(currentMonthStart, nextMonthStart) : "",
// all migrations create a partition for the next month
createScript(nextMonthStart, nextMonthEnd),
// after a desired number of partitions have been created, detach one partition
partition >= partitions ? detachScript : "",
// a detached partition from previous run can be dropped
partition >= partitions + 1 ? dropScript : "",
]
.filter((script) => script.length > 0)
.join("\n");
const migrationFileName = `${String(migration).padStart(
5,
"0"
)}_${partitionTableName(
partition === 1 ? currentMonthStart : nextMonthStart
)}.sql`;
await fs.promises.writeFile(
path.join("migrations", migrationFileName),
migrationScript
);
};
run();
create-partition.ts
Running the script five times and passing five consecutive months as parameters will create five migration files.
$ for month in 07 08 09 10 11; do
ts-node scripts/create-partition.ts 2022-${month} samples 4
done
creating partition table migration scripts
The first partition table migration script creates two partitions, one for the current month and one for the next month:
CREATE TABLE samples_2022_07
PARTITION OF samples
FOR VALUES FROM ('2022-06-30') TO ('2022-07-31');
CREATE TABLE samples_2022_08
PARTITION OF samples
FOR VALUES FROM ('2022-07-31') TO ('2022-08-31');
migrations/00002_samples_2022_07.sql
The following two scripts both create one partition.
CREATE TABLE samples_2022_09
PARTITION OF samples
FOR VALUES FROM ('2022-08-31') TO ('2022-09-30');
migrations/00003_samples_2022_09.sql
CREATE TABLE samples_2022_10
PARTITION OF samples
FOR VALUES FROM ('2022-09-30') TO ('2022-10-31');
migrations/00004_samples_2022_10.sql
The fourth migration script creates one partition and detaches the first partition.
CREATE TABLE samples_2022_11
PARTITION OF samples
FOR VALUES FROM ('2022-10-31') TO ('2022-11-30');
ALTER TABLE samples DETACH PARTITION samples_2022_07;
migrations/00005_samples_2022_11.sql
The fifth migration script creates one partition, detaches the second partition, and drops the first partition.
CREATE TABLE samples_2022_12
PARTITION OF samples
FOR VALUES FROM ('2022-11-30') TO ('2022-12-31');
ALTER TABLE samples DETACH PARTITION samples_2022_08;
DROP TABLE samples_2022_07;
migrations/00006_samples_2022_12.sql
Now the migrations can be run against the local database:
PGHOST=localhost PGPORT=5432 PGUSER=samples PGPASSWORD=samples PGDATABASE=samples node scripts/migrate.mjs
After the migrations have been run, there are four attached partitions:
$ docker exec -it postgres su -c "psql samples -c '\d+ samples'" postgres
Partitioned table "public.samples"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stat
s target | Description
--------+-------+-----------+----------+---------+----------+-------------+-----
---------+-------------
time | date | | not null | | plain | |
|
data | jsonb | | not null | | extended | |
|
Partition key: RANGE ("time")
Indexes:
"samples_time_idx" btree ("time")
Partitions: samples_2022_09 FOR VALUES FROM ('2022-08-31') TO ('2022-09-30'),
samples_2022_10 FOR VALUES FROM ('2022-09-30') TO ('2022-10-31'),
samples_2022_11 FOR VALUES FROM ('2022-10-31') TO ('2022-11-30'),
samples_2022_12 FOR VALUES FROM ('2022-11-30') TO ('2022-12-31')
And one detached partition:
$ docker exec -it postgres su -c "psql samples -c '\d samples_2022_08'" postgres
Table "public.samples_2022_08"
Column | Type | Collation | Nullable | Default
--------+-------+-----------+----------+---------
time | date | | not null |
data | jsonb | | not null |
Indexes:
"samples_2022_08_time_idx" btree ("time")
Opening Pull Requests in GitHub Actions Workflow
To ensure table partition schema migration scripts are created every month GitHub Actions workflow can be dispatched using the schedule trigger that uses CRON syntax, e.g. 0 0 1 * * triggers the workflow on the first day of every month. It can be helpful to dispatch it manually, too, with the workflow_dispatch trigger.
Database-specific configuration is better placed in a separate script than a workflow file.
#!/bin/sh
ts-node scripts/create-partition.ts $(date +%Y-%m) samples 4
The following workflow file .github/workflows/monthly-migrations.yaml does the following:
- checks out the repository with actions/checkout,
- installs node.js with actions/setup-node,
- installs dependencies, e.g., ts-node, by running
npm ci, - runs the script
scripts/create-monthly-migrations.shand - creates a pull request with peter-evans/create-pull-request.
name: Create Monthly PostgreSQL Migrations
on:
schedule:
- cron: "0 0 1 * *" # first day of every month
workflow_dispatch: # manual trigger
jobs:
monthly_migrations:
name: Create Monthly PostgreSQL Migrations
runs-on: ubuntu-latest # or use your own runners, e.g. [self-hosted, linux, x64]
steps:
- name: Checkout
uses: actions/checkout@v3 # consider using commit hashes instead of version tags for improved peace of mind
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: 16
- name: Install Dependencies
run: npm ci
- name: Create Monthly Migrations
run: ./scripts/create-monthly-migrations.sh
- name: Create Pull Request
uses: peter-evans/create-pull-request@v4
with:
author: ${{ github.actor }} <${{ github.actor }}@users.noreply.github.com>
title: "Monthly PostgreSQL Migrations"
body: "PostgreSQL migration scripts that should be run monthly against the database."
branch: monthly-postgresql-migrations
.github/workflows/monthly-migrations.yaml
The script scripts/create-monthly-migrations.sh calls scripts/create-partition.ts with appropriate parameters:
#!/bin/sh
TS_NODE=./node_modules/ts-node/dist/bin.js
$TS_NODE scripts/create-partition.ts $(date +%Y-%m) samples 4
scripts/create-monthly-migrations.sh (if you run it with npm through package.json scripts, ts-node can be run without relative path)
After committing the workflow file to the repository it is possible to dispatch it under the "Actions" tab.
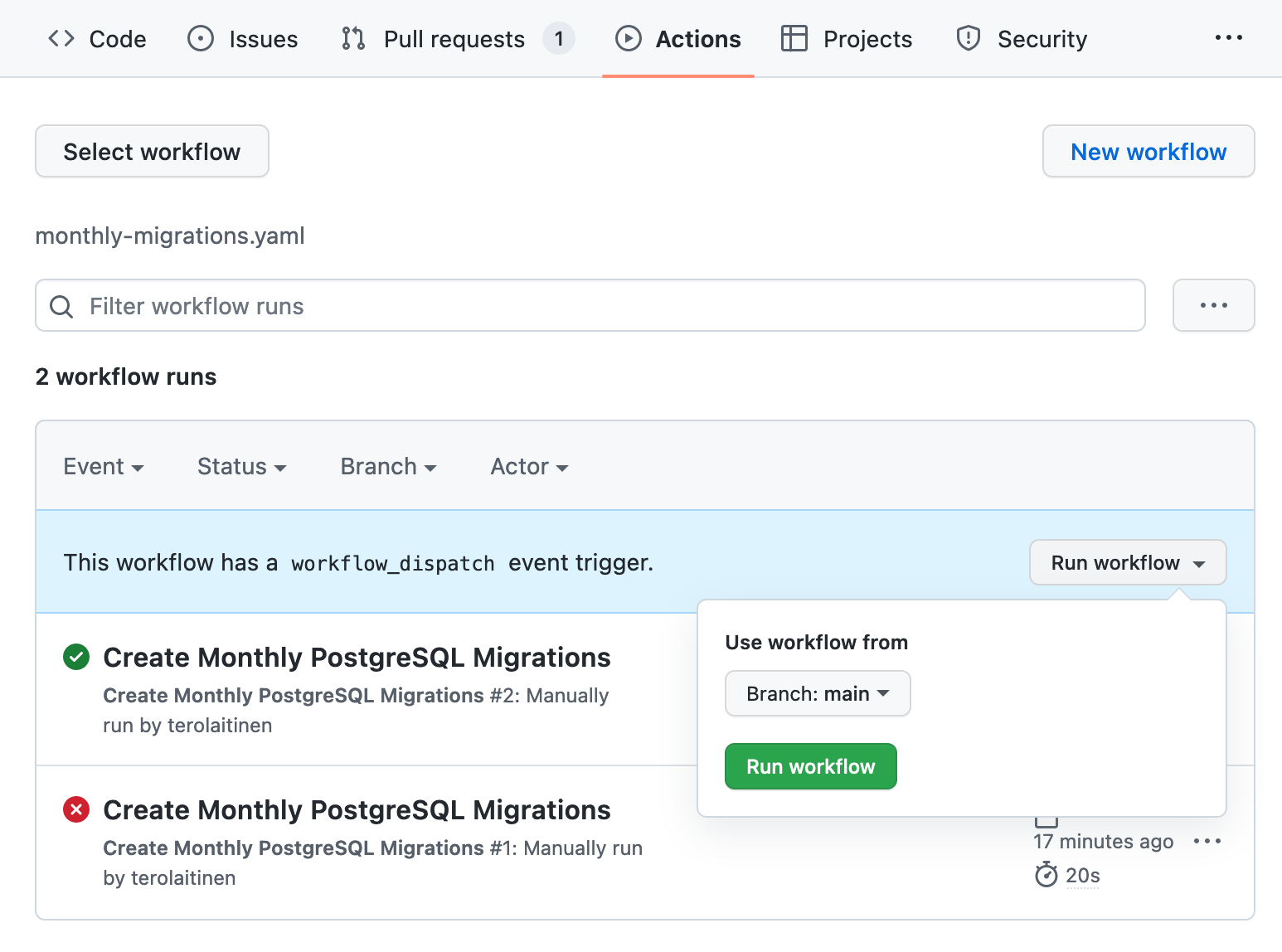
dispatching GitHub Actions workflow manually
A successful workflow run results in a newly opened pull request:
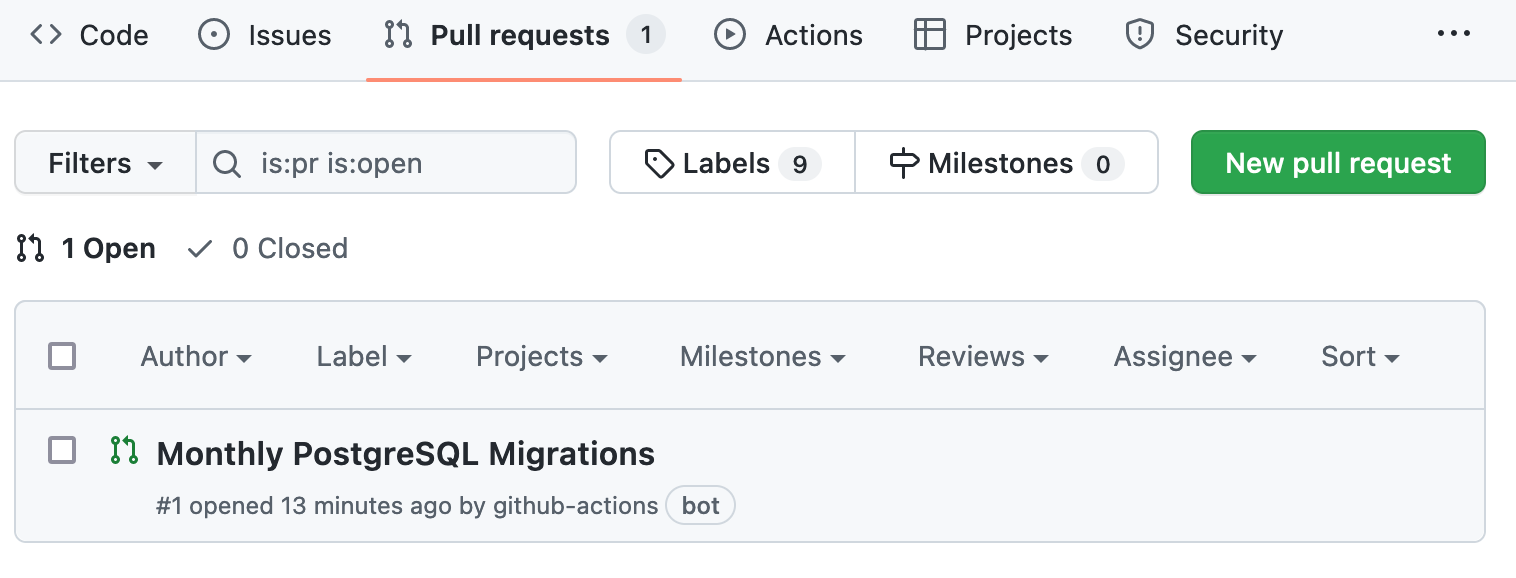
pull request opened by GitHub Actions workflow
The pull request includes a commit to add the file migrations/00002_samples_2022_07.sql:
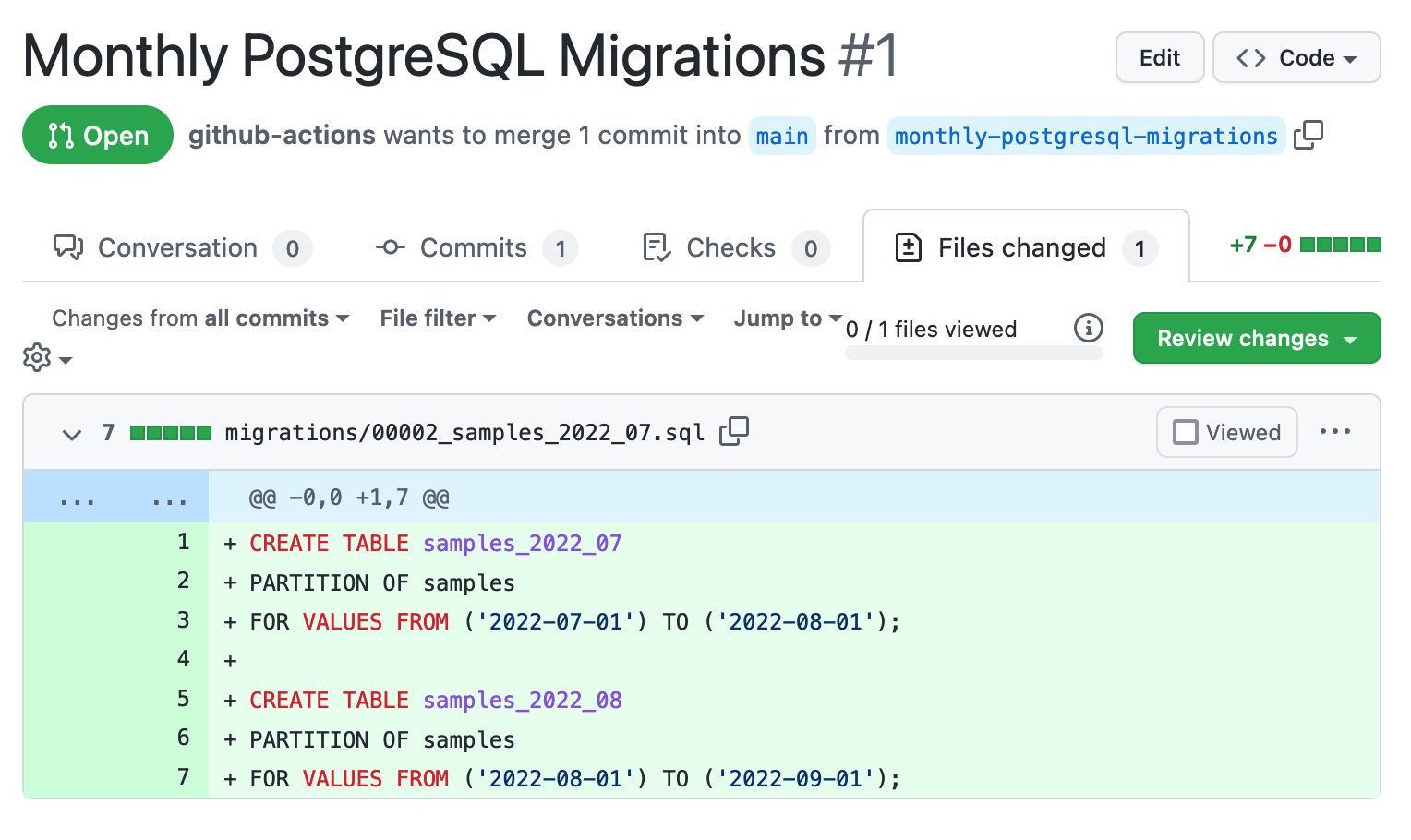
schema migration created by GitHub Actions workflow
It is possible to merge such pull requests automatically with peter-evans/enable-pull-request-automerge to avoid creating schema migration scripts with the same numeric prefix (00002 here). However, auto-merging is available only for public and non-free private repositories.
Conclusions
Partitioning a PostgreSQL table can speed up queries and help archive rows that are no longer used actively. Managing a partitioned table requires recurring updates to the database schema, and these should be handled as versioned and incremental schema migration scripts. Schema migration scripts to create, detach and drop partitions are highly regular, and their creation should be automated. Creating schema migration scripts programmatically is a good start, but it is better to push the automation further to ensure schema migrations are regularly and correctly created. GitHub Actions and postgres-migrations can be leveraged with the help of a short script and a workflow definition to periodically open pull requests that add appropriate schema migration scripts.